
1、简述
控制器(controller)是Kafka集群中的一个核心组件,负责管理和协调集群的状态。
任何一个 broker 都可以作为 controller,但是每个集群任意时刻只能有一个controller。
2、职责
- 更新集群元数据信息
- 创建 topic
- 删除 topic
- 分区重分配
- preferred leader 副本选举
- topic 分区扩展
- broker 加入集群
- broker 崩溃
- 受控关闭
- controller leader 选举
3、组件

4、原理
4.1、Broker 启动
Broker在启动时,会启动一个Controller 服务,代码如下:
def startup() {
...
// 1、Controller创建
kafkaController = new KafkaController(config, zkUtils, brokerState, time, metrics, threadNamePrefix)
// 2、Controller启动
kafkaController.startup()
...
}
4.2、Controller 创建
流程如下:
- 创建Controller上下文
- 创建分区状态机
- 创建副本状态机
- 创建Controller选举器
- 创建Topic删除管理器
- 创建4种不同的Leader选举器
- 创建ControllerBrokerRequestBatch,用于将发往同-个broker的各种请求按照类型分组,统一发送以提高效率(有3种类型请求:UpdateMetadata、LeaderAndIsr、StopReplica)
- 创建6种不同的监听器
8.1. 监听Broker上下线(/brokers/ids)
8.2. 监听主题的变化(/brokers/topics)
8.3. 监听分区的变化(/brokers/topics/<TOPIC_NAME>)
8.4. 监听分区重分配(/admin/reassign_partitions)
8.5. 监听最优副本选举(/admin/preferred_replica_election)
8.6. 监听ISR变化(/isr_change_notification)
源码如下:
class KafkaController(...) extends Logging with KafkaMetricsGroup {
// 1、创建Controller上下文
val controllerContext = new ControllerContext(zkUtils)
// 2、创建分区状态机
val partitionStateMachine = new PartitionStateMachine(this)
// 3、创建副本状态机
val replicaStateMachine = new ReplicaStateMachine(this)
// 4、创建Controller选举器
private val controllerElector = new ZookeeperLeaderElector(...)
// 5、创建Topic删除管理器
var deleteTopicManager: TopicDeletionManager = null
// 6、创建4种不同的Leader选举器
val offlinePartitionSelector = new OfflinePartitionLeaderSelector(controllerContext, config)
val reassignedPartitionLeaderSelector = new ReassignedPartitionLeaderSelector(controllerContext)
val preferredReplicaPartitionLeaderSelector = new PreferredReplicaPartitionLeaderSelector(controllerContext)
val controlledShutdownPartitionLeaderSelector = new ControlledShutdownLeaderSelector(controllerContext)
// 7、将发往同-个broker的各种请求按照类型分组,统一发送以提高效率(有3种类型请求:UpdateMetadata、LeaderAndIsr、StopReplica)
private val brokerRequestBatch = new ControllerBrokerRequestBatch(this)
// 8、创建6种不同的监听器
// 监听Broker上下线(/brokers/ids)
private val brokerChangeListener = new BrokerChangeListener(this, eventManager)
// 监听主题的变化(/brokers/topics)
private val topicChangeListener = new TopicChangeListener(this, eventManager
// 监听分区的变化(/brokers/topics/<TOPIC_NAME>)
private val partitionModificationsListeners: mutable.Map[String, PartitionModificationsListener] = mutable.Map.empty
// 监听分区重分配(/admin/reassign_partitions)
private val partitionReassignmentListener = new PartitionReassignmentListener(this, eventManager)
// 监听最优副本选举(/admin/preferred_replica_election)
private val preferredReplicaElectionListener = new PreferredReplicaElectionListener(this, eventManager)
// 监听ISR变化(/isr_change_notification)
private val isrChangeNotificationListener = new IsrChangeNotificationListener(this, eventManager)
}
4.3、Controller 启动
调用kafkaController的startup方法,controller启动后,并不保证当前 broker 是 controller,它只是注册了Session失效监听器和Controller变化监听器,然后进行Controller选举
def startup() = {
eventManager.put(Startup)
eventManager.start()
}
case object Startup extends ControllerEvent {
def state = ControllerState.ControllerChange
override def process(): Unit = {
// 1、注册SessionExpirationListener
registerSessionExpirationListener
// 2、注册Controller变化监听器(/controller)
registerControllerChangeListener()
// 3、Controller选举
elect()
}
}
4.4、Controller 选举
Controller选举器启动后,流程如下:
- 从 zk 获取数据解析出当前的 controller id(不存在则为-1)
- 若id不为-1,说明 controller 已经存在,退出选举流程
- 若id为-1,说明 controller 不存在,则可以进行选举
- zk创建临时节点/controller,并写入数据("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp)
4.1. 若注册成功,当前 broker 选举成为 controller
4.2. 若注册失败
4.2.1. 若是因为controller已存在了,则更新缓存
4.2.2. 若是因为抛出异常了,则重置所有数据
源码如下:
def elect: Boolean = {
val timestamp = time.milliseconds
// broker要向zk的/controller节点写的数据("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp)
val electString = Json.encode(Map("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp.toString))
// 1、从 zk 获取数据解析出当前的 controller id(不存在则为-1)
activeControllerId = getControllerID()
// 2、若id不为-1,说明 controller 已经存在,退出选举流程
if(activeControllerId != -1) {
return
}
// 3、若id为-1,说明 controller 不存在,则可以进行选举
try {
// 4、zk创建临时节点/controller,并写入数据("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp)
val zkCheckedEphemeral = new ZKCheckedEphemeral(ZkUtils.ControllerPath,
electString,
controllerContext.zkUtils.zkConnection.getZookeeper,
controllerContext.zkUtils.isSecure)
zkCheckedEphemeral.create()
// 4.1、若注册成功,当前 broker 选举成为 controller
activeControllerId = config.brokerId
onControllerFailover()
} catch {
// 4.2、若注册失败
// 4.2.1、若是因为controller已存在,则更新缓存
case _: ZkNodeExistsException =>
activeControllerId = getControllerID
// 4.2.2、若是因为抛出异常,则重置所有数据
case e2: Throwable =>
triggerControllerMove()
}
}
// 从 zk的/controller节点获取数据解析出当前的 controller id,若不存在,则返回-1
def getControllerID(): Int = {
controllerContext.zkUtils.readDataMaybeNull(ZkUtils.ControllerPath)._1 match {
case Some(controller) => KafkaController.parseControllerId(controller)
// controller不存在,则返回-1
case None => -1
}
private def triggerControllerMove(): Unit = {
onControllerResignation()
activeControllerId = -1
controllerContext.zkUtils.deletePath(ZkUtils.ControllerPath)
}
4.5、Controller 初始化
上一小节 Controller 选举,当前 broker 成功选举为 controller 后,会调用 onControllerFailover方法初始化。
流程如下:
- 从 zk 的 /controller_epoch节点 获取 controller 的 epoch 和 version 值
- Controller 的 epoch 自增加1 (若 /controller_epoch不存在则创建)
- 注册分区重分配监听(/admin/reassign_partitions)
- 注册ISR变动监听(/isr_change_notification)
- 注册最优Leader选举监听(/admin/preferred_replica_election)
- 注册主题变化监听(/brokers/topics)
- 注册主题删除监听(/admin/delete_topics)
- 注册Broker上下线监听(/brokers/ids)
- 初始化 controller 上下文
- 向集群中的所有Broker发送更新元数据的请求
- 启动副本状态机
- 启动分区状态机
- 为所有的 topic 注册监听器(/brokers/topics/<TOPIC_NAME>,监听Partition扩容)
- 尝试触发分区的重分配
- 尝试删除需要被删除的主题
- 最优副本选举
- 开启Leader自动平衡任务(当auto.leader.rebalance.enable=true时)
源码如下:
def onControllerFailover() {
// 从 zk 的 /controller_epoch节点 获取 controller 的 epoch 和 version 值
readControllerEpochFromZookeeper()
// Controller 的 epoch 自增加1 (若 /controller_epoch不存在则创建)
incrementControllerEpoch(zkUtils.zkClient)
// 注册分区重分配监听(/admin/reassign_partitions)
registerPartitionReassignmentListener()
// 注册ISR变动监听(/isr_change_notification)
registerIsrChangeNotificationListener()
// 注册最优Leader选举监听(/admin/preferred_replica_election)
registerPreferredReplicaElectionListener()
// 注册主题变化监听(/brokers/topics)
registerTopicChangeListener()
// 注册主题删除监听(/admin/delete_topics)
registerTopicDeletionListener()
// 注册Broker上下线监听(/brokers/ids)
registerBrokerChangeListener()
// 初始化 controller 上下文
initializeControllerContext()
val (topicsToBeDeleted, topicsIneligibleForDeletion) = fetchTopicDeletionsInProgress()
topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)
// 向集群中的所有Broker发送更新元数据的请求
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)
// 启动副本状态机
replicaStateMachine.startup()
// 启动分区状态机
partitionStateMachine.startup()
// 为所有的 topic 注册监听器(/brokers/topics/<TOPIC_NAME>,监听Partition扩容)
controllerContext.allTopics.foreach(topic => partitionStateMachine.registerPartitionChangeListener(topic))
// 尝试触发分区的重分配
maybeTriggerPartitionReassignment
// 尝试删除需要被删除的主题
topicDeletionManager.tryTopicDeletion()
val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections()
// 最优副本的选举
onPreferredReplicaElection(pendingPreferredReplicaElections)
kafkaScheduler.startup()
// 开启Leader自动平衡任务(auto.leader.rebalance.enable=true时)
if (config.autoLeaderRebalanceEnable) {
scheduleAutoLeaderRebalanceTask(delay = 5, unit = TimeUnit.SECONDS)
}
}
4.6、Controller 上下文
上一小节Controller初始化中,会调用initializeControllerContext方法初始化ControllerContext。ControllerContext维护了集群的所有元数据信息。

private def initializeControllerContext() {
// 1、从 zk 获取所有 alive broker 列表
controllerContext.liveBrokers = zkUtils.getAllBrokersInCluster().toSet
// 2、从 zk 获取所有的 topic 列表
controllerContext.allTopics = zkUtils.getAllTopics().toSet
// 3、从 zk 获取所有 Partition 的 replica 信息
controllerContext.partitionReplicaAssignment = zkUtils.getReplicaAssignmentForTopics(controllerContext.allTopics.toSeq)
// 4、从 zk 获取所有 Partition 的 LeaderAndIsr 信息
controllerContext.partitionLeadershipInfo = new mutable.HashMap[TopicAndPartition, LeaderIsrAndControllerEpoch]
// 5、正在关闭中的broker列表
controllerContext.shuttingDownBrokerIds = mutable.Set.empty[Int]
// 6、更新Leader和ISR缓存
updateLeaderAndIsrCache()
// 7、启动 Channel Manager
startChannelManager()
// 8、初始化需要最优 leader 选举的 Partition 列表
initializePreferredReplicaElection()
// 9、初始化需要进行副本迁移的 Partition 列表
initializePartitionReassignment()
// 10、初始化需要删除的 topic 列表及 TopicDeletionManager 对象
initializeTopicDeletion()
info("Currently active brokers in the cluster: %s".format(controllerContext.liveBrokerIds))
info("Currently shutting brokers in the cluster: %s".format(controllerContext.shuttingDownBrokerIds))
info("Current list of topics in the cluster: %s".format(controllerContext.allTopics))
}
4.7、Controller 监听
ControllerChangeListener 用于监听 zk 上的 /controller 节点变化。如果该节点内容变化,则触发 handleDataChange方法; 如果节点被删除,则触发 handleDataDeleted 方法。
流程如下:
- 如果 /controller 节点有变化,解析出最新的 controller id,然后做比对,当前broker若之前是controller,现在不是了,则执行 controller关闭操作;
- 如果 /controller 节点被删除,如果当前broker之前是 controller,那么先执行 controller 关闭操作,再执行 controller重新选举。
源码如下:
class ControllerChangeListener(controller: KafkaController, eventManager: ControllerEventManager) extends IZkDataListener
// controller修改
override def handleDataChange(dataPath: String, data: Any): Unit = {
eventManager.put(controller.ControllerChange(KafkaController.parseControllerId(data.toString)))
}
// controller删除
override def handleDataDeleted(dataPath: String): Unit = {
eventManager.put(controller.Reelect)
}
}
controller修改后的逻辑:
case class ControllerChange(newControllerId: Int) extends ControllerEvent {
def state = ControllerState.ControllerChange
override def process(): Unit = {
// 判断broker之前是否是Controller
val wasActiveBeforeChange = isActive
activeControllerId = newControllerId
if (wasActiveBeforeChange && !isActive) {
// broker之前是Controller,现在不是了,执行关闭操作
onControllerResignation()
}
}
}
// 判断broker之前是否是Controller
def isActive: Boolean = activeControllerId == config.brokerId
controller删除后的逻辑:
case object Reelect extends ControllerEvent {
def state = ControllerState.ControllerChange
override def process(): Unit = {
// 判断broker之前是否是Controller
val wasActiveBeforeChange = isActive
activeControllerId = getControllerID()
if (wasActiveBeforeChange && !isActive) {
// broker之前是Controller,现在不是了,执行关闭操作
onControllerResignation()
}
// 重新选举
elect()
}
}
// 判断broker之前是否是Controller
def isActive: Boolean = activeControllerId == config.brokerId
4.8、Controller 下线
上一小节,当监听到 zk 上的 /controller 节点有变化时,若broker之前是 controller,现在不是了,则需要执行controller下线操作。
流程如下:
- 解除ISR变化监听
- 解除分区重分区监听
- 解除最优副本选举监听
- 重置主题删除管理器
- 关闭Leader自动平衡调度器
- 解除正在进行的分区重分配ISR变化监听
- 关闭分区状态机
- 解除主题变化监听
- 解除分区变化监听
- 解除主题删除监听
- 关闭副本状态机
- 解除Broker上下线监听
- 重置Controller上下文
源码如下:
def onControllerResignation() {
// 解除ISR变化监听
deregisterIsrChangeNotificationListener
// 解除分区重分区监听
deregisterReassignedPartitionsListener()
// 解除最优副本选举监听
deregisterPreferredReplicaElectionListener()
// 重置主题删除管理器
if (deleteTopicManager != null)
topicDeletionManager.reset()
// 关闭Leader自动平衡调度器
kafkaScheduler.shutdown()
offlinePartitionCount = 0
preferredReplicaImbalanceCount = 0
// 解除正在进行的分区重分配ISR变化监听
deregisterPartitionReassignmentIsrChangeListeners()
// 关闭分区状态机
partitionStateMachine.shutdown()
// 解除主题变化监听
deregisterTopicChangeListener()
// 解除分区变化监听
partitionModificationsListeners.keys.foreach(deregisterPartitionModificationsListener)
// 解除主题删除监听
deregisterTopicDeletionListener()
// 关闭副本状态机
replicaStateMachine.shutdown()
// 解除Broker变化监听
deregisterBrokerChangeListener()
// 重置Controller上下文
resetControllerContext()
}
4.9、Leader 选举器
Controller在创建时,创建了初始化4种不同的 leader选举器,如下:
// 初始化
class KafkaController(...) extends Logging with KafkaMetricsGroup {
...
// 初始化4种不同的 leader 选举器
val offlinePartitionSelector = new OfflinePartitionLeaderSelector(controllerContext, config)
val reassignedPartitionLeaderSelector = new ReassignedPartitionLeaderSelector(controllerContext)
val preferredReplicaPartitionLeaderSelector = new PreferredReplicaPartitionLeaderSelector(controllerContext)
val controlledShutdownPartitionLeaderSelector = new ControlledShutdownLeaderSelector(controllerContext)
...
}
4.9.1、OfflinePartitionLeaderSelector
当Leader下线后,选举出新的Leader
选举规则:
- 找AR中第一个存活的且在ISR中的副本
- 若找不到,且unclean.leader.election.enable为true,则找AR中第一个存活的副本
选举流程:
OfflinePartitionLeaderSelector Partition leader 选举的逻辑是:
- 当ISR中有至少一个存活的副本时
1.1. AR中第一个存活的副本并且在ISR中的副本,选举为新的Leader
1.2. ISR中存活的副本作为新的ISR,leaderEpoch和zkVersion自增1 - 当ISR中没有存活的副本时
2.1. 当unclean.leader.election.enable为false,抛出 NoReplicaOnlineException 异常
2.2. 当unclean.leader.election.enable为true
2.2.1. AR中的存活的副本为空,抛出 NoReplicaOnlineException 异常
2.2.2. AR中的存活的副本不为空
2.2.2.1. AR中第一个存活的副本,选举为新的Leader
2.2.2.2. 新的Leader加入ISR,leaderEpoch和zkVersion自增1
源码如下:
class OfflinePartitionLeaderSelector(...) extends PartitionLeaderSelector {
// leader 选举
def selectLeader(topicAndPartition: TopicAndPartition, currentLeaderAndIsr: LeaderAndIsr): (LeaderAndIsr, Seq[Int]) = {
controllerContext.partitionReplicaAssignment.get(topicAndPartition) match {
case Some(assignedReplicas) =>
// AR中的存活的副本
val liveAssignedReplicas = assignedReplicas.filter(r => controllerContext.liveBrokerIds.contains(r))
// ISR中的存活的副本
val liveBrokersInIsr = currentLeaderAndIsr.isr.filter(r => controllerContext.liveBrokerIds.contains(r))
val currentLeaderEpoch = currentLeaderAndIsr.leaderEpoch
val currentLeaderIsrZkPathVersion = currentLeaderAndIsr.zkVersion
val newLeaderAndIsr =
// 1、当ISR中有至少一个存活的副本时
if (!liveBrokersInIsr.isEmpty) {
// 1.1、AR中第一个存活的副本并且在ISR中的副本,选举为新的Leader
val liveReplicasInIsr = liveAssignedReplicas.filter(r => liveBrokersInIsr.contains(r))
val newLeader = liveReplicasInIsr.head
// 1.2、ISR中存活的副本作为新的ISR,leaderEpoch和zkVersion自增1
new LeaderAndIsr(newLeader, currentLeaderEpoch + 1, liveBrokersInIsr.toList, currentLeaderIsrZkPathVersion + 1)
} else {
// 2、当ISR中没有存活的副本时
// 2.1、当unclean.leader.election.enable为false,抛出 NoReplicaOnlineException 异常
if (!LogConfig.fromProps(config.originals, AdminUtils.fetchEntityConfig(controllerContext.zkUtils,
ConfigType.Topic, topicAndPartition.topic)).uncleanLeaderElectionEnable) {
throw new NoReplicaOnlineException(("No broker in ISR for partition " +
"%s is alive. Live brokers are: [%s],".format(topicAndPartition, controllerContext.liveBrokerIds)) +
" ISR brokers are: [%s]".format(currentLeaderAndIsr.isr.mkString(",")))
}
debug("No broker in ISR is alive for %s. Pick the leader from the alive assigned replicas: %s"
.format(topicAndPartition, liveAssignedReplicas.mkString(",")))
// 2.2、当unclean.leader.election.enable为true
// 2.2.1、AR中的存活的副本为空,抛出 NoReplicaOnlineException 异常
if (liveAssignedReplicas.isEmpty) {
throw new NoReplicaOnlineException(("No replica for partition " +
"%s is alive. Live brokers are: [%s],".format(topicAndPartition, controllerContext.liveBrokerIds)) +
" Assigned replicas are: [%s]".format(assignedReplicas))
} else {
// 2.2.2、AR中的存活的副本不为空
// 2.2.2.1、AR中第一个存活的副本,选举为新的Leader
ControllerStats.uncleanLeaderElectionRate.mark()
val newLeader = liveAssignedReplicas.head
// 2.2.2.2、新的Leader加入ISR,leaderEpoch和zkVersion自增1
new LeaderAndIsr(newLeader, currentLeaderEpoch + 1, List(newLeader), currentLeaderIsrZkPathVersion + 1)
}
}
(newLeaderAndIsr, liveAssignedReplicas)
case None =>
throw new NoReplicaOnlineException("Partition %s doesn't have replicas assigned to it".format(topicAndPartition))
}
}
}
4.9.2、ReassignedPartitionLeaderSelector
分区副本重分配,之前的Leader副本在经过重分配之后不存在了,需要选举出新的Leader
选举规则:
从重分配的 AR 列表中找到第一个存活的且在ISR中的副本
源码如下:
class ReassignedPartitionLeaderSelector(...) extends PartitionLeaderSelector {
def selectLeader(topicAndPartition: TopicAndPartition, currentLeaderAndIsr: LeaderAndIsr): (LeaderAndIsr, Seq[Int]) = {
val reassignedInSyncReplicas = controllerContext.partitionsBeingReassigned(topicAndPartition).newReplicas
val currentLeaderEpoch = currentLeaderAndIsr.leaderEpoch
val currentLeaderIsrZkPathVersion = currentLeaderAndIsr.zkVersion
// 从重分配的AR列表中找到第一个存活的且在ISR中的副本
val aliveReassignedInSyncReplicas = reassignedInSyncReplicas.filter(r => controllerContext.liveBrokerIds.contains(r) &&
currentLeaderAndIsr.isr.contains(r))
val newLeaderOpt = aliveReassignedInSyncReplicas.headOption
newLeaderOpt match {
case Some(newLeader) => (new LeaderAndIsr(newLeader, currentLeaderEpoch + 1, currentLeaderAndIsr.isr,
currentLeaderIsrZkPathVersion + 1), reassignedInSyncReplicas)
case None =>
reassignedInSyncReplicas.size match {
case 0 =>
throw new NoReplicaOnlineException("List of reassigned replicas for partition " +
" %s is empty. Current leader and ISR: [%s]".format(topicAndPartition, currentLeaderAndIsr))
case _ =>
throw new NoReplicaOnlineException("None of the reassigned replicas for partition " +
"%s are in-sync with the leader. Current leader and ISR: [%s]".format(topicAndPartition, currentLeaderAndIsr))
}
}
}
}
4.9.3、PreferredReplicaPartitionLeaderSelector
优先副本选举
触发场景:
- 手动分区平衡:手动执行优先副本选举脚本 kafka-leader-election.sh
- 自动分区平衡:自动定时执行Leader重平衡任务(当auto.leader.rebalance.enable=true时)
选举规则:
AR中的第一个副本是存活的,且在ISR中,则被选为Leader,否则抛出异常
选举流程:
1、判断AR中的第一个副本是否是当前Leader
1.1、若是,则抛出LeaderElectionNotNeededException异常
1.2、若否,则执行优先副本选举
1.2.1、若AR中的第一个副本存活且在ISR中,则被选为Leader
1.2.2、否则,抛出StateChangeFailedException异常
源码如下:
class PreferredReplicaPartitionLeaderSelector(...) extends PartitionLeaderSelector {
def selectLeader(topicAndPartition: TopicAndPartition, currentLeaderAndIsr: LeaderAndIsr): (LeaderAndIsr, Seq[Int]) = {
// AR中的副本集合
val assignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition)
// AR中的第一个副本
val preferredReplica = assignedReplicas.head
// 1、判断AR中的第一个副本是否是当前Leader
val currentLeader = controllerContext.partitionLeadershipInfo(topicAndPartition).leaderAndIsr.leader
// 1.1、若是,则抛出LeaderElectionNotNeededException异常
if (currentLeader == preferredReplica) {
throw new LeaderElectionNotNeededException("Preferred replica %d is already the current leader for partition %s"
.format(preferredReplica, topicAndPartition))
} else {
// 1.2、若否,则执行优先副本选举
// 1.2.1、若AR中的第一个副本存活且在ISR中,则被选为Leader
if (controllerContext.liveBrokerIds.contains(preferredReplica) && currentLeaderAndIsr.isr.contains(preferredReplica)) {
(new LeaderAndIsr(preferredReplica, currentLeaderAndIsr.leaderEpoch + 1, currentLeaderAndIsr.isr,
currentLeaderAndIsr.zkVersion + 1), assignedReplicas)
} else {
// 1.2.2、否则,抛出StateChangeFailedException异常
throw new StateChangeFailedException("Preferred replica %d for partition ".format(preferredReplica) +
"%s is either not alive or not in the isr. Current leader and ISR: [%s]".format(topicAndPartition, currentLeaderAndIsr))
}
}
}
}
4.9.4、ControlledShutdownLeaderSelector
触发场景:
用脚本kafka-server - stop.sh 关闭broker时,位于这个节点上的leader 副本都会下线,与此对应的分区需要执行 leader的选举。
选举规则:
在AR中找到第一个满足条件的副本:AR中存活的 && 在ISR中的 && 所在的broker没有在下线。
源码如下:
class ControlledShutdownLeaderSelector(...) extends PartitionLeaderSelector {
def selectLeader(topicAndPartition: TopicAndPartition, currentLeaderAndIsr: LeaderAndIsr): (LeaderAndIsr, Seq[Int]) = {
val currentLeaderEpoch = currentLeaderAndIsr.leaderEpoch
val currentLeaderIsrZkPathVersion = currentLeaderAndIsr.zkVersion
val currentLeader = currentLeaderAndIsr.leader
val assignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition)
val liveOrShuttingDownBrokerIds = controllerContext.liveOrShuttingDownBrokerIds
// AR中的存活的副本
val liveAssignedReplicas = assignedReplicas.filter(r => liveOrShuttingDownBrokerIds.contains(r))
// 当前ISR中过滤掉正在下线的broker
val newIsr = currentLeaderAndIsr.isr.filter(brokerId => !controllerContext.shuttingDownBrokerIds.contains(brokerId))
// 第一个满足条件的副本(AR中存活的副本 && ISR中的副本 && 所在的broker没有在下线)被选为Leader
liveAssignedReplicas.find(newIsr.contains) match {
case Some(newLeader) =>
(LeaderAndIsr(newLeader, currentLeaderEpoch + 1, newIsr, currentLeaderIsrZkPathVersion + 1), liveAssignedReplicas)
case None =>
throw new StateChangeFailedException(("No other replicas in ISR %s for %s besides" +
" shutting down brokers %s").format(currentLeaderAndIsr.isr.mkString(","), topicAndPartition, controllerContext.shuttingDownBrokerIds.mkString(",")))
}
}
}
4.10、副本状态机
Replica State Machine
副本状态机一共定义了 7 种状态,如下:
1、NewReplica
Controller 创建副本时的最初状态 。当处在这个状态时 ,副本只能成为follower 副本 。
2、OnlineReplica
启动副本后变更为该状态。在该状态下,副本既可以成为 follower 副本也可以成为 leader 副本。
3、OfflineReplica
一旦副本所在 broker 崩溃,该副本将变更为该状态 。
4、ReplicaDeletionStarted
若开启了 topic 删除操作, topic下所有分区的所有副本都会被删除 。 此时副本进入该状态 。
5、ReplicaDeletionSuccessful
若副本成功响应了删除副本请求,则进入该状态。
6、ReplicaDeletionlneligible
若副本删除失败,则进入该状态 。
7、NonExistentReplica
若副本被成功删除,则进入该状态 。

创建topic 后,该topic 下所有分区的所有副本处于 NonExistent 状态。然后 controller读取 zk 中该 topic 的分配方案到内存中,同时将副本状态变更为 NewReplica,之后 controller 选举出该分区的leader 和ISR,然后在 zk 中持久化该决定。
一旦确定了分区的 leader 和 ISR 之后, controller 会将这些信息以请求的方式发送给所有副本,同时将这些副本状态同步到集群的所有 broker 上以便让它们知晓。当这些都做完后,controller 会将分区的所有副本状态置为 Online ,这也是副本正常工作的状态 。
当开启了 topic 删除操作时, controller 会尝试停止所有副本,此时副本将停止向 leader 获取数据,但若停止的副本就是 leader 副本本身,则 controller 会设置该分区的 leader 为 NO LEADER,之后副本进入 Offline 状态。一旦所有副本进入 Offline 状态, controller 需要将副本进一步变更到 ReplicaDeletionStarted 状态,表明删除 topic 任务的开启。在这一步的状态流转中, controller 会给这些副本所在的 broker 发送请求,让它们删除本机上的副本数据 。一旦删除成功,这些副本就变更到 ReplicaDeletionSuccessful 状态;如果有失败的副本,那么该副本进入 ReplicaDeletionlneligible 状态表明暂时还无法删除该副本,等待 controller 的重试。
那些处于 ReplicaDeletionSuccessful 状态的副本稍后会被自动地变更到 NonExistent 终止状态,同时 controller 的上下文缓存会清除这些副本信息。这就是副本状态机操作副本状态流转的典型场景 。
4.10.1、创建
private val controllerContext = controller.controllerContext
private val controllerId = controller.config.brokerId
private val zkUtils = controllerContext.zkUtils
// 所有副本的状态信息
private val replicaState: mutable.Map[PartitionAndReplica, ReplicaState] = mutable.Map.empty
private val brokerChangeListener = new BrokerChangeListener(controller)
private val brokerRequestBatch = new ControllerBrokerRequestBatch(controller)
private val hasStarted = new AtomicBoolean(false)
4.10.2、初始化
流程如下:
- 初始化所有副本的状态
1.1. 若副本是存活的,则将状态转移至OnlineReplica
1.2. 若副本不在了,则将状态移至ReplicaDeletionIneligible - 将所有存活的副本状态移至OnlineReplica
源码如下:
def startup() {
// 1、初始化所有副本的状态
initializeReplicaState()
hasStarted.set(true)
// 2、将存活的副本状态转移至OnlineReplica
handleStateChanges(controllerContext.allLiveReplicas(), OnlineReplica)
}
private def initializeReplicaState() {
for((topicPartition, assignedReplicas) <- controllerContext.partitionReplicaAssignment) {
val topic = topicPartition.topic
val partition = topicPartition.partition
assignedReplicas.foreach { replicaId =>
val partitionAndReplica = PartitionAndReplica(topic, partition, replicaId)
// 1.1、若副本是存活的,则将状态转移至OnlineReplica
if (controllerContext.liveBrokerIds.contains(replicaId))
replicaState.put(partitionAndReplica, OnlineReplica)
else
// 1.2、若副本不在了,则将状态转移至ReplicaDeletionIneligible
replicaState.put(partitionAndReplica, ReplicaDeletionIneligible)
}
}
}
def handleStateChanges(...) {
if(replicas.nonEmpty) {
try {
brokerRequestBatch.newBatch()
// 2.1、副本状态转移
replicas.foreach(r => handleStateChange(r, targetState, callbacks))
// 2.2、向broker发送请求
brokerRequestBatch.sendRequestsToBrokers(controller.epoch)
}catch {
case e: Throwable => error(...)
}
}
}
状态转移流程如下:
- 若副本不存在,状态初始化为 NonExistentReplica
- 副本各种状态之间的转移
2.1. 副本前置状态校检
2.2. 副本状态转移
状态转移源码如下:
def handleStateChange(partitionAndReplica: PartitionAndReplica, targetState: ReplicaState, callbacks: Callbacks) {
val topic = partitionAndReplica.topic
val partition = partitionAndReplica.partition
val replicaId = partitionAndReplica.replica
val topicAndPartition = TopicAndPartition(topic, partition)
// 1、副本当前的状态,若副本不存在,状态初始化为 NonExistentReplica
val currState = replicaState.getOrElseUpdate(partitionAndReplica, NonExistentReplica)
try {
val replicaAssignment = controllerContext.partitionReplicaAssignment(topicAndPartition)
// 2、副本各种状态之间的转移(currState--> targetState)
targetState match {
case NewReplica =>
// 2.1、副本前置状态校检(currState--> NewReplica)
// 2.2、副本状态转移具体逻辑(currState--> NewReplica)
case ReplicaDeletionStarted =>
...
case ReplicaDeletionIneligible =>
...
case ReplicaDeletionSuccessful =>
...
case NonExistentReplica =>
...
case OnlineReplica =>
...
case OfflineReplica =>
...
}
}
catch {
case t: Throwable =>
stateChangeLogger.error(...)
}
}
4.10.3、状态转移
4.10.3.1、状态转移至NewReplica
触发条件:
- 新增主题(TopicChangeListener监听 /brokers/topics)
- 新增主题分区(PartitionModificationsListener 监听 /brokers/topics/<TOPIC_NAME>)
- 新分配的副本
流程如下:
- 副本前置状态校检(前置状态只能是NonExistentReplica)
- 从zk中获取分区的元数据(leader. ISR. epoch)
2.1. 若副本是leader,状态不能被转移至NewReplica
2.2. 若副本不是leader,向该副本所在的broker发送LeaderAndIsr请求,向所有的broker发送UpdateMetadata请求,更新元数据 - 副本状态转移到NewReplica
源码如下:
// 1、副本前置状态校检(前置状态只能是NonExistentReplica)
assertValidPreviousStates(partitionAndReplica, List(NonExistentReplica), targetState)
// 2、从zk中获取分区的元数据(leader、ISR、epoch)
val leaderIsrAndControllerEpochOpt = ReplicationUtils.getLeaderIsrAndEpochForPartition(zkUtils, topic, partition)
leaderIsrAndControllerEpochOpt match {
case Some(leaderIsrAndControllerEpoch) =>
// 2.1、若副本是leader,状态不能被转移至NewReplica
if(leaderIsrAndControllerEpoch.leaderAndIsr.leader == replicaId)
throw new StateChangeFailedException(...)
// 2.2、若副本不是leader,向该副本所在的broker发送LeaderAndIsr请求,向所有的broker发送UpdateMetadata请求,更新元数据
brokerRequestBatch.addLeaderAndIsrRequestForBrokers(List(replicaId),
topic, partition, leaderIsrAndControllerEpoch,
replicaAssignment)
case None =>
}
// 3、副本状态转移到NewReplica
replicaState.put(partitionAndReplica, NewReplica)
4.10.3.2、状态转移至OnlineReplica
触发条件:
- 新增主题后,状态先转移到NewReplica,再转移到OnlineReplica
- 新增主题分区后,状态先转移到NewReplica,再转移到OnlineReplica
- broker启动后,将该节点上的副本状态转移到OnlineReplica
- 分区重分配,RAR中的副本状态转移到OnlineReplica
- 副本状态机启动初始化时,将存活的副本状态转变为OnlineReplica
流程如下:
- 副本前置状态校检(前置状态只能是NewReplica、 OnlineReplica、 OfflineReplica、 ReplicaDeletionIneligible)
- 副本状态转移
2.1. 如果副本当前状态是NewReplica
2.1.1. 从缓存中拿到分区的副本列表
2.1.2. 若副本列表中不包含当前副本,则将该副本加入到副本列表中
2.2. 如果副本当前状态是其他状态
2.2.1. 获取该分区的元数据
2.2.2. 如果分区元数据存在,向该副本所在的broker发送请求,同步分区元数据 - 副本状态转移到OnlineReplica
源码如下:
// 1、副本前置状态校检(前置状态只能是NewReplica、OnlineReplica、OfflineReplica、ReplicaDeletionIneligible)
assertValidPreviousStates(partitionAndReplica, List(NewReplica, OnlineReplica, OfflineReplica, ReplicaDeletionIneligible), targetState)
// 2、副本状态转移
replicaState(partitionAndReplica) match {
// 2.1、如果副本当前状态是NewReplica
case NewReplica =>
// 2.1.1、从缓存中拿到分区的副本列表
val currentAssignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition)
// 2.1.2、若副本列表中不包含当前副本,则将该副本加入到副本列表中
if (!currentAssignedReplicas.contains(replicaId))
controllerContext.partitionReplicaAssignment.put(topicAndPartition, currentAssignedReplicas :+ replicaId)
// 2.2、如果副本当前状态是其他状态
case _ =>
// 2.2.1、获取该分区的元数据
controllerContext.partitionLeadershipInfo.get(topicAndPartition) match {
// 2.2.2、如果分区元数据存在,向该副本所在的broker发送请求,同步分区元数据
case Some(leaderIsrAndControllerEpoch) =>
brokerRequestBatch.addLeaderAndIsrRequestForBrokers(List(replicaId), topic, partition, leaderIsrAndControllerEpoch,replicaAssignment)
replicaState.put(partitionAndReplica, OnlineReplica)
case None =>
}
}
// 3、副本状态转移到OnlineReplica
replicaState.put(partitionAndReplica, OnlineReplica)
4.10.3.3、状态转移至OfflineReplica
触发条件:
- 新增主题(TopicChangeListener监听 /brokers/topics)
- 新增主题分区(PartitionModificationsListener 监听 /brokers/topics/<TOPIC_NAME>)
流程如下:
- 副本前置状态校检(前置状态只能是NewReplica、 OnlineReplica、 OfflineReplica、 ReplicaDeletionIneligible)
- 向副本所在的broker发送StopReplicaRequest请求,停止副本同步
- 从ISR中移除这个副本,并更新zk节点(/brokers/topics/<TOPIC_NAME>/partitions/<PARTITION_ID>/state)
- 给剩余的其他副本所在的broker发送LeaderAndIsr请求
- 优雅关闭 broker 时,目的是把下线节点上的副本状态设置为 OfflineReplica
- broker优雅关闭(ControlledShutdown)时,该节点上的副本状态转移到OfflineReplica
- broker掉线后,该节点上的副本状态转移到OfflineReplica
- 分区重分配,需要下线的副本,状态转移到OfflineReplica
- 删除失败的副本,状态转移到OfflineReplica,重新进行删除
源码如下:
// 1、副本前置状态校检(前置状态只能是NewReplica、OnlineReplica、OfflineReplica、ReplicaDeletionIneligible)
assertValidPreviousStates(partitionAndReplica,List(NewReplica, OnlineReplica, OfflineReplica, ReplicaDeletionIneligible), targetState)
// 2、向副本所在的broker发送StopReplicaRequest请求,停止副本同步
brokerRequestBatch.addStopReplicaRequestForBrokers(List(replicaId), topic, partition, deletePartition = false)
val leaderAndIsrIsEmpty: Boolean =
controllerContext.partitionLeadershipInfo.get(topicAndPartition) match {
case Some(_) =>
// 3、从ISR中移除这个副本,并更新zk节点(/brokers/topics/<TOPIC_NAME>/partitions/<PARTITION_ID>/state)
controller.removeReplicaFromIsr(topic, partition, replicaId) match {
case Some(updatedLeaderIsrAndControllerEpoch) =>
val currentAssignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition)
if (!controller.deleteTopicManager.isPartitionToBeDeleted(topicAndPartition)) {
// 4、给剩余的其他副本所在的broker发送LeaderAndIsr请求
brokerRequestBatch.addLeaderAndIsrRequestForBrokers(currentAssignedReplicas.filterNot(_ == replicaId),
topic, partition, updatedLeaderIsrAndControllerEpoch, replicaAssignment)
}
// 5、副本状态转移到OfflineReplica
replicaState.put(partitionAndReplica, OfflineReplica)
false
case None =>
true
}
case None =>
true
}
4.10.3.4、状态转移至ReplicaDeletionStarted
触发条件:
- 分区重分配,需要下线的副本(OfflineReplica-->ReplicaDeletionStarted-->ReplicaDeletionSuccessful-->NonExistentReplica)
- 新增主题分区(PartitionModificationsListener 监听 /brokers/topics/<TOPIC_NAME>)
流程如下:
- 副本前置状态校检(前置状态只能是OfflineReplica)
- 副本状态转移到ReplicaDeletionStarted
- 给副本所在的broker发送StopReplica请求
源码如下:
// 1、副本前置状态校检(前置状态只能是OfflineReplica)
assertValidPreviousStates(partitionAndReplica, List(OfflineReplica), targetState)
// 2、副本状态转移到ReplicaDeletionStarted
replicaState.put(partitionAndReplica, ReplicaDeletionStarted)
// 3、给该副本所在的broker发送StopReplica请求,并设置deletePartition=true
brokerRequestBatch.addStopReplicaRequestForBrokers(List(replicaId), topic, partition, deletePartition = true,
callbacks.stopReplicaResponseCallback)
4.10.3.5、状态转移至ReplicaDeletionSuccessful
触发条件:
- 分区重分配,需要下线的副本(OfflineReplica-->ReplicaDeletionStarted-->ReplicaDeletionSuccessful-->NonExistentReplica)
- 删除成功的副本,状态转移到ReplicaDeletionSuccessful
流程如下:
- 副本前置状态校检(前置状态只能是ReplicaDeletionStarted)
- 副本状态转移到ReplicaDeletionSuccessful
源码如下:
// 1、副本前置状态校检(前置状态只能是ReplicaDeletionStarted)
assertValidPreviousStates(partitionAndReplica, List(ReplicaDeletionStarted), targetState)
// 2、副本状态转移到ReplicaDeletionSuccessful
replicaState.put(partitionAndReplica, ReplicaDeletionSuccessful)
4.10.3.6、状态转移至ReplicaDeletionIneligible
触发条件:
- 删除失败的副本,状态转移到ReplicaDeletionIneligible
- 分区重分配,需要下线的副本(OfflineReplica-->ReplicaDeletionStarted-->ReplicaDeletionSuccessful-->NonExistentReplica)
流程如下:
- 副本前置状态校检(前置状态只能是ReplicaDeletionStarted)
- 副本状态转移到ReplicaDeletionIneligible
源码如下:
// 1、副本前置状态校检(前置状态只能是ReplicaDeletionStarted)
assertValidPreviousStates(partitionAndReplica, List(ReplicaDeletionStarted), targetState)
// 2、副本状态转移到ReplicaDeletionIneligible
replicaState.put(partitionAndReplica, ReplicaDeletionIneligible)
4.10.3.7、状态转移至NonExistentReplica
触发条件:
- 新增主题(TopicChangeListener监听 /brokers/topics)
- 新增主题分区(PartitionModificationsListener 监听 /brokers/topics/<TOPIC_NAME>)
流程如下:
- 副本前置状态校检(前置状态只能是ReplicaDeletionStarted)
- 从缓存中删掉副本
源码如下:
// 1、副本前置状态校检(前置状态只能是ReplicaDeletionSuccessful)
assertValidPreviousStates(partitionAndReplica, List(ReplicaDeletionSuccessful), targetState)
val currentAssignedReplicas = controllerContext.partitionReplicaAssignment(topicAndPartition)
// 2、从缓存中删掉副本
controllerContext.partitionReplicaAssignment.put(topicAndPartition, currentAssignedReplicas.filterNot(_ == replicaId))
replicaState.remove(partitionAndReplica)
4.11、分区状态机
Partition State Machine
除了副本状态机, controller 还引入了分区状态机来负责集群下所有分区的状态管理。
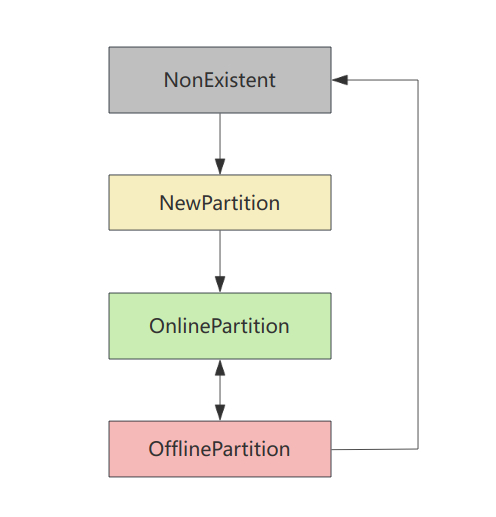
分区状态机只定义了 4 个分区状态 , 它们分别如下 :
- NonExistent
分区不存在或己被删除。
- NewPartition
分区创建后,进入此状态 。此时分区不可用,尚未选举出 leader 和 ISR。
- OnlinePartition
分区 leader 副本被选出后,进入此状态 。分区上线可正常工作。
- OfflinePartition
leader 所在 broker 宕机,分区进入此状态,无法正常工作,会触发选举产生新leader。
4.11.1、创建
private val controllerContext = controller.controllerContext
private val controllerId = controller.config.brokerId
private val zkUtils = controllerContext.zkUtils
// 所有分区的状态信息
private val partitionState: mutable.Map[TopicAndPartition, PartitionState] = mutable.Map.empty
private val brokerRequestBatch = new ControllerBrokerRequestBatch(controller)
private val hasStarted = new AtomicBoolean(false)
private val noOpPartitionLeaderSelector = new NoOpLeaderSelector(controllerContext)
private val topicChangeListener = new TopicChangeListener(controller)
private val deleteTopicsListener = new DeleteTopicsListener(controller)
private val partitionModificationsListeners: mutable.Map[String, PartitionModificationsListener] = mutable.Map.empty
private val stateChangeLogger = KafkaController.stateChangeLogger
4.11.2、初始化
流程如下:
- 初始化所有分区的状态
1.1. 遍历所有的分区
1.2. 每个分区是否有leader和isr信息
1.2.1. 若有leader和isr信息
1.2.1.1. leader在线,则将状态设转移至OnlinePartition
1.2.1.2. leader不在线,则将状态转移至OfflinePartition
1.2.2. 若没有leader和isr信息, 则将状态转移至NewPartition - 触发状态转移到OnlinePartition
2.1. 剔除将要被删除的topic
2.2. 将OfflinePartition或NewPartition状态的分区,状态转移至OnlinePartition
源码如下:
def startup() {
// 1、初始化所有分区的状态
initializePartitionState()
// 2、触发状态转移到OnlinePartition
triggerOnlinePartitionStateChange()
}
private def initializePartitionState() {
// 1.1、遍历所有的分区
for (topicPartition <- controllerContext.partitionReplicaAssignment.keys) {
// 1.2、每个分区是否有leader和isr信息
controllerContext.partitionLeadershipInfo.get(topicPartition) match {
// 1.2.1、若有leader和isr信息
case Some(currentLeaderIsrAndEpoch) =>
if (controllerContext.liveBrokerIds.contains(currentLeaderIsrAndEpoch.leaderAndIsr.leader))
// 1.2.1.1、Leader在线,则将状态设置为OnlinePartition
partitionState.put(topicPartition, OnlinePartition)
else
// 1.2.1.2、Leader不在线,则将状态设置为OfflinePartition
partitionState.put(topicPartition, OfflinePartition)
// 1.2.2、若没有leader和isr信息, 则将状态设置为NewPartition
case None =>
partitionState.put(topicPartition, NewPartition)
}
}
}
def triggerOnlinePartitionStateChange() {
try {
brokerRequestBatch.newBatch()
for ((topicAndPartition, partitionState) <- partitionState
// 2.1、剔除将要被删除的topic
if !controller.deleteTopicManager.isTopicQueuedUpForDeletion(topicAndPartition.topic)) {
// 2.2、将OfflinePartition或NewPartition状态的分区,状态转移至OnlinePartition
if (partitionState.equals(OfflinePartition) || partitionState.equals(NewPartition))
handleStateChange(topicAndPartition.topic, topicAndPartition.partition, OnlinePartition, controller.offlinePartitionSelector,
(new CallbackBuilder).build)
}
brokerRequestBatch.sendRequestsToBrokers(controller.epoch)
} catch {
case e: Throwable => error(...)
}
}
状态转移流程如下:
- 若分区不存在,状态初始化为 NonExistentPartition
- 分区各种状态之间的转移
2.1. 分区前置状态校检
2.2. 分区状态转移具体逻辑
状态转移源码如下:
private def handleStateChange(topic: String, partition: Int, targetState: PartitionState,leaderSelector: PartitionLeaderSelector, callbacks: Callbacks) {
val topicAndPartition = TopicAndPartition(topic, partition)
// 1、分区当前的状态,若分区不存在,状态初始化为 NonExistentPartition
val currState = partitionState.getOrElseUpdate(topicAndPartition, NonExistentPartition)
try {
// 2、分区各种状态之间的转移(currState--> targetState)
targetState match {
case NewPartition =>
// 2.1、分区前置状态校检(currState--> NewPartition)
// 2.2、分区状态转移具体逻辑(currState--> NewPartition)
case OnlinePartition =>
// ...
case OfflinePartition =>
// ...
case NonExistentPartition =>
// ...
}
} catch {
case t: Throwable =>
stateChangeLogger.error(...)
}
}
4.11.3、状态转移
4.11.3.1、状态转移至NewPartition
触发条件:
- 新增主题(TopicChangeListener监听 /brokers/topics)
- 新增主题分区(PartitionModificationsListener 监听 /brokers/topics/<TOPIC_NAME>)
流程如下:
- 分区前置状态校检(前置状态只能是NonExistentPartition)
- 分区状态转移到NewPartition
源码如下:
// 1、分区前置状态校检(前置状态只能是NonExistentPartition)
assertValidPreviousStates(topicAndPartition, List(NonExistentPartition), NewPartition)
// 2、分区状态转移到NewPartition
partitionState.put(topicAndPartition, NewPartition)
4.11.3.2、状态转移至OnlinePartition
触发条件:
- 新增主题后,状态先转移到NewPartition,再转移到OnlinePartition,触发选举(AR中存活的第一个副本)
- 新增主题分区后,状态先转移到NewPartition,再转移到OnlinePartition,触发选举(AR中存活的第一个副本)
- 分区状态机初始化时,遍历所有的分区
3.1. 如果分区有 LeaderAndIsr 信息,并且leader是存活的,则将分区状态转移到OnlinePartition
3.2. 如果分区有 LeaderAndIsr 信息,但是leader是不存活的,则先将分区状态转移到OfflinePartition,再转移到OnlinePartition,触发选举(OfflinePartitionLeaderSelector选举器)
3.3. 如果分区没有 LeaderAndIsr 信息,则先将分区状态转移到NewPartition,再转移到OnlinePartition,触发选举(AR中存活的第一个副本) - 分区重分配
4.1. 若新方案不包含当前的leader,状态转移到OnlinePartition,触发选举 (ReassignedPartitionLeaderSelector选举器)
4.2. 若新方案包含当前的leader,但leader所在的broker已下线,状态转移到OnlinePartition,触发选举(ReassignedPartitionLeaderSelector选举器) - 最优副本选举时,状态转移到OnlinePartition,触发选举(PreferredReplicaPartitionLeaderSelector选举器)
- broker下线后(BrokerChangeListener 监听 /brokers/ids),leader在这个broker上的分区,状态先转移到OfflinePartition,再转移到OnlinePartition,触发选举(OfflinePartitionLeaderSelector选举器)
- broker优雅关闭(ControlledShutdown)时,位于这个节点上的leader 副本都会下线,状态转移到 OnlinePartition,触发选举 (ControlledShutdownLeaderSelector选举器)
流程如下:
- 分区前置状态校检(前置状态只能是NewPartition、OnlinePartition、OfflinePartition)
- 分区状态转移,选举出leader、ISR,并更新zk和缓存
2.1. 若是NewPartition-->OnlinePartition ,leader选举(AR中存活的第一个副本)
2.2. 若是OfflinePartition-->OnlinePartition,leader选举(OfflinePartitionLeaderSelector选举器)
2.3. 若是OnlinePartition-->OnlinePartition ,leader选举(ReassignedPartitionLeaderSelector. PreferredReplicaPartitionLeaderSelector、ControlledShutdownLeaderSelector选举器) - 分区状态转移到OnlinePartition
源码如下:
// 1、分区前置状态校检(前置状态只能是NewPartition、OnlinePartition、OfflinePartition)
assertValidPreviousStates(topicAndPartition, List(NewPartition, OnlinePartition, OfflinePartition), OnlinePartition)
// 2、分区状态转移
partitionState(topicAndPartition) match {
// 2.1、若是NewPartition-->OnlinePartition
case NewPartition =>
initializeLeaderAndIsrForPartition(topicAndPartition)
// 2.2、若是OfflinePartition-->OnlinePartition
case OfflinePartition =>
electLeaderForPartition(topic, partition, leaderSelector)
// 2.3、若是OnlinePartition-->OnlinePartition
case OnlinePartition =>
electLeaderForPartition(topic, partition, leaderSelector)
case _ =>
}
// 3、分区状态转移到NewPartition
partitionState.put(topicAndPartition, OnlinePartition)
4.11.3.2.1、NewPartition-->OnlinePartition
触发条件:
- 新增主题后,状态先转移到NewPartition,再转移到OnlinePartition
- 新增主题分区后,状态先转移到NewPartition,再转移到OnlinePartition
流程如下:
- AR中存活的第一个副本,选举为leader
- AR中存活的副本集合,为ISR
- zk上创建一个持久节点,/brokers/topics/<TOPIC_NAME>/partitions/<PARTITION_ID>/state
- 写入分区的元数据信息(leader、isr、leader_epoch、controller_epoch、version)
- 更新本地缓存
- 向所有的broker发送请求更新信息
源码如下:
private def initializeLeaderAndIsrForPartition(topicAndPartition: TopicAndPartition) {
val replicaAssignment = controllerContext.partitionReplicaAssignment(topicAndPartition)
val liveAssignedReplicas = replicaAssignment.filter(r => controllerContext.liveBrokerIds.contains(r))
liveAssignedReplicas.size match {
case 0 =>
throw new StateChangeFailedException(failMsg)
case _ =>
// 1、AR中存活的第一个副本,选举为leader
val leader = liveAssignedReplicas.head
// 2、AR中存活的副本集合,为ISR
val leaderIsrAndControllerEpoch = new LeaderIsrAndControllerEpoch(new LeaderAndIsr(leader, liveAssignedReplicas.toList), controller.epoch)
try {
// 3、zk上创建一个持久节点,/brokers/topics/<TOPIC_NAME>/partitions/<PARTITION_ID>/state
// 4、写入分区的元数据信息(leader、isr、leader_epoch、controller_epoch、version)
zkUtils.createPersistentPath(
getTopicPartitionLeaderAndIsrPath(topicAndPartition.topic, topicAndPartition.partition),
zkUtils.leaderAndIsrZkData(leaderIsrAndControllerEpoch.leaderAndIsr, controller.epoch))
// 5、更新本地缓存
controllerContext.partitionLeadershipInfo.put(topicAndPartition, leaderIsrAndControllerEpoch)
// 6、向所有的broker发送请求更新信息
brokerRequestBatch.addLeaderAndIsrRequestForBrokers(liveAssignedReplicas, topicAndPartition.topic,
topicAndPartition.partition, leaderIsrAndControllerEpoch, replicaAssignment)
} catch {
case _: ZkNodeExistsException =>
throw new StateChangeFailedException(failMsg)
}
}
}
4.11.3.2.2、OfflinePartition-->OnlinePartition
流程如下:
- 从zk中读取分区元数据(从/brokers/topics/<TOPIC_NAME>/partitions/<PARTITION_ID>/state节点下读取)
- 若zk中的controller epoch比当前缓存中的epoch大,说明当前controller是无效的,退出流程
- 为分区选举leader(使用的OfflinePartitionLeaderSelector选举器)
- 更新zk上的分区元数据
- 更新本地缓存
- 向所有的broker发送请求更新信息
源码如下:
def electLeaderForPartition(topic: String, partition: Int, leaderSelector: PartitionLeaderSelector) {
val topicAndPartition = TopicAndPartition(topic, partition)
try {
var zookeeperPathUpdateSucceeded: Boolean = false
var newLeaderAndIsr: LeaderAndIsr = null
var replicasForThisPartition: Seq[Int] = Seq.empty[Int]
while(!zookeeperPathUpdateSucceeded) {
// 1、从zk中读取分区元数据(从/brokers/topics/<TOPIC_NAME>/partitions/<PARTITION_ID>/state节点下读取)
val currentLeaderIsrAndEpoch = getLeaderIsrAndEpochOrThrowException(topic, partition)
val currentLeaderAndIsr = currentLeaderIsrAndEpoch.leaderAndIsr
val controllerEpoch = currentLeaderIsrAndEpoch.controllerEpoch
// 2、若zk中的controller epoch比当前缓存中的epoch大,说明当前controller是无效的,退出流程
if (controllerEpoch > controller.epoch) {
throw new StateChangeFailedException(failMsg)
}
// 3、为分区选举leader(使用的OfflinePartitionLeaderSelector选举器)
val (leaderAndIsr, replicas) = leaderSelector.selectLeader(topicAndPartition, currentLeaderAndIsr)
// 4、更新zk上的分区元数据
val (updateSucceeded, newVersion) = ReplicationUtils.updateLeaderAndIsr(zkUtils, topic, partition,
leaderAndIsr, controller.epoch, currentLeaderAndIsr.zkVersion)
newLeaderAndIsr = leaderAndIsr
newLeaderAndIsr.zkVersion = newVersion
zookeeperPathUpdateSucceeded = updateSucceeded
replicasForThisPartition = replicas
}
// 5、更新本地缓存
val newLeaderIsrAndControllerEpoch = new LeaderIsrAndControllerEpoch(newLeaderAndIsr, controller.epoch)
controllerContext.partitionLeadershipInfo.put(TopicAndPartition(topic, partition), newLeaderIsrAndControllerEpoch)
val replicas = controllerContext.partitionReplicaAssignment(TopicAndPartition(topic, partition))
// 6、向所有的broker发送请求更新信息
brokerRequestBatch.addLeaderAndIsrRequestForBrokers(replicasForThisPartition, topic, partition,
newLeaderIsrAndControllerEpoch, replicas)
} catch {
}
}
4.11.3.2.3、OnlinePartition-->OnlinePartition
流程如下:
- 从zk中读取分区元数据(从/brokers/topics/<TOPIC_NAME>/partitions/<PARTITION_ID>/state节点下读取)
- 若zk中的controller epoch比当前缓存中的epoch大,说明当前controller是无效的,退出流程
- 为分区选举leader(ReassignedPartitionLeaderSelector、PreferredReplicaPartitionLeaderSelector、ControlledShutdownLeaderSelector选举器)
- 更新zk上的分区元数据
- 更新本地缓存
- 向所有的broker发送请求更新信息
源码同上
4.11.3.3、状态转移至OfflinePartition
触发条件:
- 主题删除后,先转移到OfflinePartition,再转移到NonExistentPartition
- broker下线后(BrokerChangeListener 监听 /brokers/ids),leader在这个broker上的分区,状态先转移到OfflinePartition,再转移到OnlinePartition,触发leader选举(OfflinePartitionLeaderSelector选举器)
流程如下:
- 分区前置状态校检(前置状态只能是NewPartition、OnlinePartition、OfflinePartition)
- 分区状态转移到OfflinePartition
源码如下:
// 1、分区前置状态校检(前置状态只能是NewPartition、OnlinePartition、OfflinePartition)
assertValidPreviousStates(topicAndPartition, List(NewPartition, OnlinePartition, OfflinePartition), OfflinePartition)
// 2、分区状态转移到OfflinePartition
partitionState.put(topicAndPartition, OfflinePartition)
4.11.3.4、状态转移至NonExistentPartition
触发条件:
主题删除后,先转移到OfflinePartition,再转移到NonExistentPartition
流程如下:
- 分区前置状态校检(前置状态只能是OfflinePartition)
- 分区状态转移到NonExistentPartition
源码如下:
// 1、分区前置状态校检(前置状态只能是OfflinePartition)
assertValidPreviousStates(topicAndPartition, List(OfflinePartition), NonExistentPartition)
// 2、分区状态转移到NonExistentPartition
partitionState.put(topicAndPartition, NonExistentPartition)