
上一篇: 第7篇:项目复盘与技术总结
一、写在前面
量化项目做完后,整套技术栈也逐渐清晰起来:
- LightGBM 做预测(股价涨跌)
- OR-Tools 做优化(投资组合)
- Tushare 拿数据
有天刷GitHub,看到菜鸟开源的快递数据集——LaDe(Last-mile Delivery)。1067万个包裹、21000个快递员、6个月真实运营数据。这是业界第一个公开的末端配送数据集。
看着这数据,突然冒出个想法:快递调度是不是也能用量化那套技术?
仔细一想,还真挺像:
| 量化交易 | 快递调度 | 用的技术 |
|---|---|---|
| 预测股价涨跌 | 预测包裹量 | LightGBM |
| 优化投资组合 | 优化配送路线 | OR-Tools |
| 回测验证策略 | 验证准确度 | 类似方法 |
本质都是"预测 + 优化"。
而且快递场景感觉更实用:
- 需求预测准了,能省人力成本
- 路线优化好了,能减少配送距离
- 这些都是实打实的降本增效
更关键的是,OR-Tools在物流场景更有用武之地:
- TSP(旅行商问题)- 配送路线优化
- VRP(车辆路径问题)- 多车调度
- VRPTW(带时间窗的VRP)- 上门取件
这不就是OR-Tools的经典应用场景吗?
正好量化项目的代码可以复用,改动量应该不大。试试看,能不能把一套技术用在两个完全不同的场景上。
于是有了这个快递调度系列。和量化系列一样,这里用的也是真实工业数据,不搞模拟数据。
二、快递公司的痛点在哪?
2.1 包裹量波动太大
先看看真实数据告诉我们什么。我分析了LaDe数据集里吉林市的配送数据(2022年5-10月,6个月,3.1万单):
- 日均包裹量:193单
- 最大日包裹:434单(5月29日)
- 正常波动范围:50-400单
注意:数据集在10月28日截止,10月下旬(20-28日)包裹量骤降至1-6单/天,这是数据采集结束导致的边界效应,不是真实业务波动。实际分析时应剔除这些不完整的天数。
即便如此,包裹量波动依然很大:高峰期(618前后)是平时的2倍多。
痛点就在于:资源配置特别难。按平均值配人手吧,高峰期肯定爆仓;按峰值配吧,平时又浪费一大半。很多公司就是凭经验拍脑袋,效果嘛...你懂的。
2.2 配送时效差异大
真实数据里,配送时长也很有意思:
吉林(小城市):
- 平均配送时长:3.39小时
- 中位数:2.92小时
上海(大城市):
- 平均配送时长:1.71小时
原因很简单:大城市配送密度高,快递员一趟能送好几单,不用跑太远。小城市地广人稀,送一单可能要跑好几公里。
2.3 成本控制压力山大
快递是薄利行业,一单可能就赚几块钱。这点利润,稍微浪费点就没了:
- 路线不优化,多跑10公里油钱就白干
- 人员闲置,人工成本也是成本
- 车辆利用率低,固定成本摊不下来
三、数据能干什么?
3.1 预测包裹量
最直接的应用就是预测:
- 短期预测(1-7天):用于排班、调车
- 中期预测(1-3个月):决定要不要多招几个全职快递员
- 长期预测(1年以上):决定在哪儿开新网点
3.2 优化配送路线
这个就是经典的VRP问题(车辆路径问题)。简单说,就是给定一堆配送点,怎么规划路线最省时省力。
3.3 网点选址
这个更偏战略层面。比如要在一个新城区开网点,开在哪儿最合适?覆盖范围怎么划分?
这得结合包裹数据、人口数据、竞争对手分布等等,做个优化模型。
四、LaDe数据集介绍
4.1 什么是LaDe?
LaDe(Last-mile Delivery)是菜鸟AI团队2024年在KDD会议上发布的数据集。这是业界第一个公开的末端配送数据集。
规模:
- 1067万个包裹
- 21000个快递员
- 6个月运营数据(2022年5-10月)
- 5个城市:上海、杭州、重庆、吉林、烟台
数据包含什么:
- 包裹信息(订单ID、时间、位置)
- 快递员信息(快递员ID、接单/完成时间)
- GPS轨迹(接单位置、配送位置)
- AOI信息(区域类型)
4.2 为什么用真实数据?
之前很多教程都是用模拟数据演示。但模拟数据有个大问题:太理想化了。
真实世界的快递数据:
- 有异常值(系统故障、极端天气)
- 有缺失值(GPS没上报)
- 波动性远超预期
- 规律被噪音掩盖
用真实数据学习,你才能知道实际落地时会遇到什么问题。
4.3 数据下载
数据托管在HuggingFace上,可以免费下载:
pip install huggingface_hub
huggingface-cli download Cainiao-AI/LaDe-D --repo-type dataset --local-dir ./data/raw/delivery
也可以去GitHub仓库查看详情:https://github.com/wenhaomin/LaDe
各城市数据规模:
- 上海:218MB(最大)
- 杭州:274MB
- 重庆:139MB
- 烟台:31MB
- 吉林:4.6MB(最小,适合入门)
建议先从吉林数据开始,数据量小,跑得快,容易看出规律。
4.4 整体数据规模
5个城市的基础数据(2022年5-10月,约6个月):
| 城市 | 包裹数 | 快递员 | 日均包裹 | 平均时长(h) | 中位时长(h) | 人均包裹 |
|---|---|---|---|---|---|---|
| 吉林 | 31,415 | 57 | 193 | 3.39 | 2.92 | 551 |
| 烟台 | 206,431 | 205 | 1,122 | 4.04 | 3.42 | 1,007 |
| 重庆 | 931,351 | 1,494 | 5,062 | 3.27 | 2.45 | 623 |
| 杭州 | 1,861,600 | 1,392 | 10,117 | 2.49 | 1.92 | 1,337 |
| 上海 | 1,483,864 | 1,733 | 8,064 | 1.74 | 1.20 | 856 |
关键发现:
- 包裹量差距大:杭州日均1万单,是吉林的52倍
- 大城市更快:上海平均1.74小时送达,吉林需要3.39小时
为什么大城市配送更快?
- 包裹密度高,快递员一趟能送多单
- 配送距离短,不用跨区
- 基础设施好,路况通畅
4.5 数据字段说明
LaDe-P(取件数据):
| 字段 | 名称 | 类型 |
|---|---|---|
| package_id | 包裹ID | Id |
| time_window_start/end | 时间窗口 | Time |
| lng/lat | 经纬度 | Float |
| city | 城市 | String |
| region_id | 区域ID | String |
| aoi_id / aoi_type | AOI信息 | Id / Categorical |
| courier_id | 快递员ID | Id |
| accept_time | 接单时间 | Time |
| accept_gps_lng/lat | 接单GPS坐标 | Float |
| pickup_time | 取件时间 | Time |
| pickup_gps_lng/lat | 取件GPS坐标 | Float |
| ds | 日期 | Date |
LaDe-D(派送数据):
| 字段 | 名称 | 类型 |
|---|---|---|
| package_id | 包裹ID | Id |
| lng/lat | 经纬度 | Float |
| city | 城市 | String |
| region_id | 区域ID | Id |
| aoi_id / aoi_type | AOI信息 | Id / Categorical |
| courier_id | 快递员ID | Id |
| accept_time | 接单时间 | Time |
| accept_gps_lng/lat | 接单GPS坐标 | Float |
| delivery_time | 送达时间 | Time |
| delivery_gps_lng/lat | 送达GPS坐标 | Float |
| ds | 日期 | Date |
4.6 数据可视化
上海在LaDe-P下的时空分布(图片来自官方):
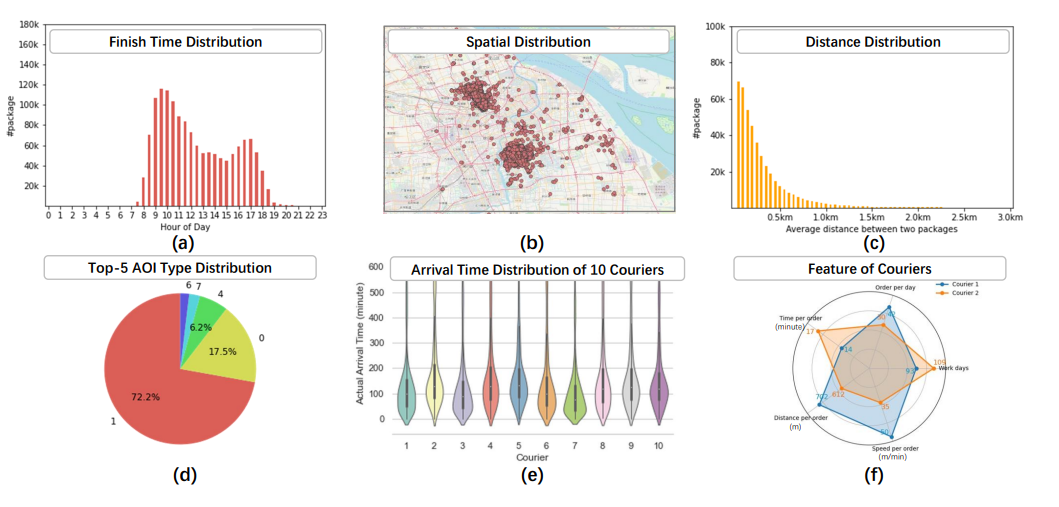
- 图(a):快递员工作时间从早8:00到晚19:00,包裹揽收量在9:00和17:00出现峰值
- 图(b)(c):包裹的空间分布,体现连续两个包裹之间的距离
- 图(d):超过70%的包裹来自AOI类型1
- 图(e):大部分包裹会在3小时内完成揽收
- 图(f):不同快递员在工作天数、日均订单量上存在差异
杭州、吉林两座城市的时空分布对比(图片来自官方):
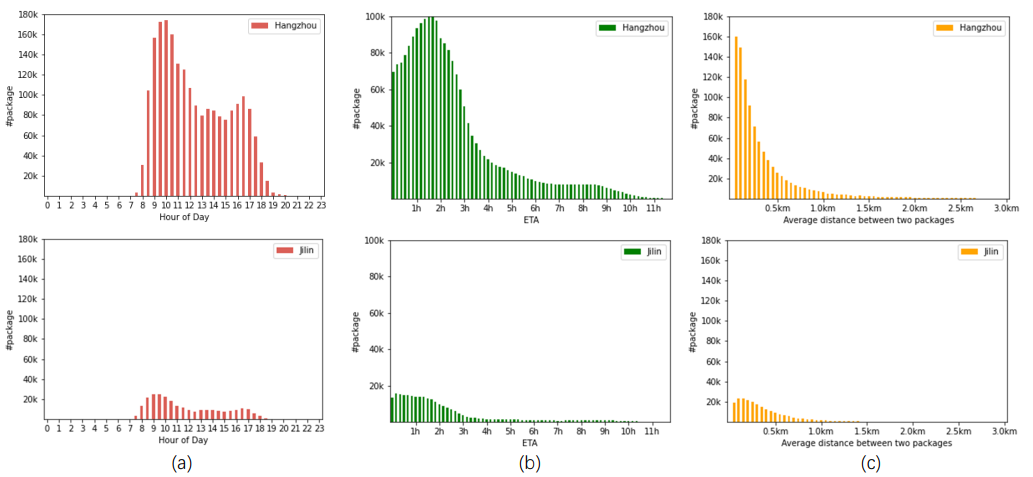
可以观察到显著的城市间差异:包裹时间分布、ETA分布、连续包裹间距都不一样。
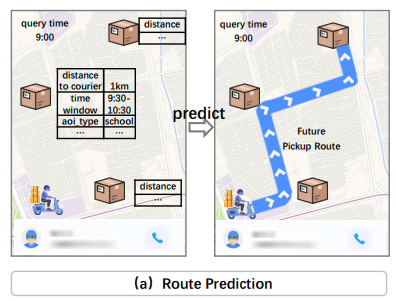
4.7 应用场景
路线预测:预测快递员未来的揽收路线
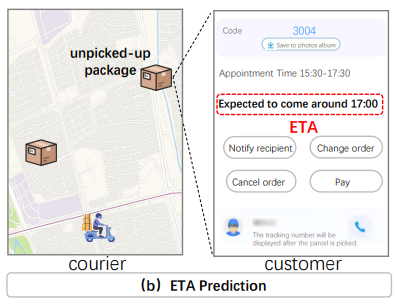
ETA预测:预估快递员揽收或派送包裹时的到达时间
时空流量预测:预测给定区域未来的包裹数量
五、代码实现
下面以吉林为例,展示完整的数据分析代码(其他城市只需修改文件名)。
5.1 数据加载
先装几个库:
pip install pandas numpy matplotlib seaborn
然后加载数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# 读取吉林数据
df = pd.read_csv('data/raw/delivery/delivery_jl.csv')
print(f"数据量: {len(df):,} 条")
print(df.columns.tolist())
print(df.head())
数据字段说明:
order_id:订单编号courier_id:快递员IDds:日期(MMDD格式)accept_time:接单时间delivery_time:完成时间accept_gps_lng/lat:接单位置delivery_gps_lng/lat:完成位置aoi_id/aoi_type:区域信息
5.2 数据预处理
# 时间字段转换
df['ds'] = pd.to_datetime('2022-' + df['ds'], format='%Y-%m%d')
df['accept_time'] = pd.to_datetime('2022-' + df['accept_time'],
format='%Y-%m-%d %H:%M:%S', errors='coerce')
df['delivery_time'] = pd.to_datetime('2022-' + df['delivery_time'],
format='%Y-%m-%d %H:%M:%S', errors='coerce')
print(f"时间范围: {df['ds'].min()} 到 {df['ds'].max()}")
print(f"覆盖天数: {df['ds'].nunique()}")
print(f"快递员数量: {df['courier_id'].nunique()}")
# 计算配送时长
df['duration_hours'] = (df['delivery_time'] - df['accept_time']).dt.total_seconds() / 3600
# 过滤异常值(负数或超长时间)
df_clean = df[(df['duration_hours'] > 0) & (df['duration_hours'] < 24)].copy()
print(f"\n清洗前: {len(df):,}")
print(f"清洗后: {len(df_clean):,}")
print(f"去除异常: {len(df) - len(df_clean):,} 条 ({(len(df) - len(df_clean))/len(df)*100:.1f}%)")
真实数据里有5-10%的异常值,这很正常。可能是系统故障、GPS漂移、或者快递员忘记点确认。
5.3 基础统计
# 每日包裹量
daily_orders = df_clean.groupby('ds').size()
print("【包裹量统计】")
print(f"日均包裹量: {daily_orders.mean():.0f}")
print(f"最大日包裹: {daily_orders.max():,}")
print(f"最小日包裹: {daily_orders.min():,}")
print(f"标准差: {daily_orders.std():.0f}")
# 配送时长
print("\n【配送时长】")
print(f"平均: {df_clean['duration_hours'].mean():.2f} 小时")
print(f"中位数: {df_clean['duration_hours'].median():.2f} 小时")
# 快递员工作量
courier_orders = df_clean.groupby('courier_id').size()
print("\n【快递员工作量】")
print(f"平均每人配送: {courier_orders.mean():.0f} 单")
print(f"最多: {courier_orders.max():,} 单")
print(f"最少: {courier_orders.min():,} 单")
运行结果(吉林真实数据):
【包裹量统计】
日均包裹量: 193
最大日包裹: 434
最小日包裹: 1
标准差: 88
【配送时长】
平均: 3.39 小时
中位数: 2.92 小时
【快递员工作量】
平均每人配送: 551 单
最多: 3,512 单
最少: 1 单
分析:
- 标准差88单,接近日均193单的一半,说明包裹量波动很大
- 有的快递员送了3512单(半年),有的只送了1单(可能是临时工)
- 配送时长中位数2.92小时,说明大部分包裹3小时内搞定
六、系列文章概览
这个系列共4篇文章,从预测到优化,从简单到复杂:
第1篇 - 快递行业的数据驱动决策概述(本篇)
- 分析5个城市的真实快递数据
- 发现行业痛点和优化空间
- LaDe数据集介绍和使用
第2篇 - 92.8%的包裹消失了:一次数据异常追踪
- 发现LaDe数据集的重大异常
- 分析5个城市配送数据完整性
- 真实数据探索和问题定位
第3篇 - 配送路线优化(TSP)
- 用OR-Tools优化配送路径
- 真实案例:34个配送点,节省43%距离
- Web界面交互式展示
第4篇 - 上门取件路线优化(VRPTW)
- 带时间窗口约束的路径问题
- 真实案例:14个取件点,距离节省34%,准时率从21%提升到100%
七、总结
快递行业看着挺传统,其实有很多可以数据化、智能化的地方。很多时候一个简单的预测模型、一个路径优化算法,就能省不少钱、提高不少效率。
用真实数据的好处:
- 能看到真实世界的复杂性
- 知道哪些假设是对的,哪些是错的
- 预测准确率更现实
真实数据的挑战:
- 有异常值、缺失值,需要清洗
- 波动性大,预测难度高
- 规律被噪音掩盖