
上一篇: 第1篇:开篇 - 量化系统从零到一
一、写在前面
上一篇讲了整个系统的架构,这篇开始进入具体实现。第一步就是数据获取,这也是最基础的一步。
说实话,一开始我以为数据获取很简单,不就是调个API下载数据嘛。但真正做起来才发现,数据质量的好坏直接决定了后面所有工作的成败。脏数据进去,再好的模型也没用。
二、数据源的选择
做量化第一个问题就是:数据从哪来?
2.1 调研过程
我前后看了几个数据源:
- Wind/彭博:专业金融数据库,数据质量最高。但太贵了,个人用不起。
- Yahoo Finance:免费,数据也全。但国内访问经常超时,不太稳定。
- Akshare:开源免费,接口简单,A股覆盖也全。但有个实际问题:爬虫性质的接口稳定性一般,批量下载经常被限流,重试逻辑一复杂,代码就乱了。
- Tushare Pro:需要积分,但接口是真正的API,稳定性比Akshare好得多。
2.2 最终选择:Tushare
最终选了Tushare,主要是两个原因:
- 稳定:正经的API服务,不是爬虫,批量下载几百只股票不会被封
- 数据质量高:复权因子由Tushare自行生产,精度有保证
最关键的是 pro_bar 接口,前复权数据一次调用直接拿到,不需要自己手动计算:
import tushare as ts
ts.set_token('your_token')
pro = ts.pro_api()
# 前复权日线数据,一行搞定
df = ts.pro_bar(ts_code='600519.SH', adj='qfq',
start_date='20150101', end_date='20241231', api=pro)
注意 Tushare 的股票代码格式和其他数据源不一样,需要带交易所后缀:沪市用 .SH,深市用 .SZ。
三、股票池选择
数据源确定了,下一个问题是:下载哪些股票?
3.1 从5只到800只
一开始只打算下5只代表性股票验证流程。但想了想,这个项目要展示的是完整的量化能力,数据量太少说服力不够。
最终方案:沪深300 + 中证500,共800只,10年历史数据(2015-2024)
3.2 为什么选这个范围
- 沪深300:A股市值最大的300只,代表大盘蓝筹
- 中证500:市值排名301-800的股票,代表中盘成长
- 两者合计800只,覆盖了A股绝大多数有投资价值的股票,互相没有重叠
- 10年跨度:覆盖了2015年牛市、2018年熊市、2020年疫情冲击、2022年下跌等各种市场环境,样本充分
3.3 获取成分股列表
成分股列表通过Akshare获取(只用于拿代码,不拉行情):
import akshare as ak
# 获取沪深300成分股
hs300 = ak.index_stock_cons_csindex(symbol='000300')
# 获取中证500成分股
zz500 = ak.index_stock_cons_csindex(symbol='000905')
转换成Tushare格式的代码:
def to_tushare_code(code, exchange):
return code + ('.SH' if '上海' in exchange else '.SZ')
四、代码实现
4.1 整体设计
数据获取相关功能封装成 StockDataLoader 类:
class StockDataLoader:
def __init__(self, data_dir='data', token=TUSHARE_TOKEN):
self.data_dir = data_dir
ts.set_token(token)
self.pro = ts.pro_api()
def get_stock_list(self, market='主板', top_n=50):
"""获取股票列表"""
pass
def download_stock_data(self, symbol, start_date, end_date):
"""下载单只股票前复权数据"""
pass
def clean_data(self, df):
"""数据清洗"""
pass
def download_multiple_stocks(self, symbols, start_date, end_date, delay=0.4):
"""批量下载,含限速"""
pass
4.2 下载单只股票
def download_stock_data(self, symbol, start_date='20150101', end_date='20241231'):
"""用 pro_bar 下载前复权日线数据"""
df = ts.pro_bar(
ts_code=symbol,
adj='qfq',
start_date=start_date,
end_date=end_date,
api=self.pro
)
if df is None or len(df) == 0:
return None
df = df.rename(columns={'trade_date': 'date', 'vol': 'volume'})
df['date'] = pd.to_datetime(df['date'])
df['symbol'] = symbol
df = df.sort_values('date').reset_index(drop=True)
return df
4.3 数据清洗:三层过滤
def clean_data(self, df):
# 第一层:删除核心字段缺失的行
df = df.dropna(subset=['open', 'high', 'low', 'close', 'volume'])
# 第二层:过滤停牌日(成交量为0)
df = df[df['volume'] > 0]
# 第三层:过滤异常涨跌幅(>30%,可能是数据错误)
df['return'] = df['close'].pct_change()
df = df[abs(df['return']) <= 0.3]
df = df.drop('return', axis=1)
return df.sort_values('date').reset_index(drop=True)
为什么不填充缺失值?
缺了就是缺了,用前一天的数据填充相当于在造假数据。后续特征工程里RSI、MACD这些指标都依赖OHLCV,缺一个就算不对,还不如直接删掉。
停牌的影响
停牌期间成交量为0,价格不变。如果不过滤:
- 收益率会出现大量假的"0"
- 动量指标(RSI、MACD)会在停牌期间锁死在某个值
- 模型会学到错误的模式:"价格不变 = 收益率为零"
30% 的阈值
A股涨跌停限制:普通股票 ±10%,科创板/创业板 ±20%,北交所±30%
4.4 批量下载:断点续传 + 限速
800只股票不可能一口气下完,需要考虑两个问题:网络中断和API限速。
# download_index_data.py
CACHE_DIR = 'data/cache_parquet' # 每只股票单独缓存
for i, ts_code in enumerate(todo, 1):
for attempt in range(3): # 失败自动重试3次
try:
df = download_one(ts_code)
df.to_parquet(f'{CACHE_DIR}/{ts_code}.parquet', compression='snappy')
break
except Exception as e:
time.sleep((attempt + 1) * 5)
time.sleep(0.4) # 每次请求间隔400ms,避免超出限速
断点续传逻辑:
# 已缓存的股票直接跳过
done = {f.replace('.parquet', '') for f in os.listdir(CACHE_DIR)}
todo = [s for s in stocks if s not in done]
这样中途断了可以直接重跑,不会从头开始。
五、数据存储:为什么选 Parquet
之前用CSV存,换成Parquet之后几个明显的好处:
| 对比项 | CSV | Parquet |
|---|---|---|
| 文件大小 | 大 | 极小(压缩率极高) |
| 读取速度 | 慢 | 极快 |
| 类型保存 | 不保存(date每次要重新parse) | 保存(date直接是datetime) |
| 列过滤 | 读完整个文件再筛 | 只读需要的列 |
读写方式和CSV完全一样:
# 保存
df.to_parquet('data/stock_data.parquet', index=False, compression='snappy')
# 读取(date列自动是datetime类型,不用parse_dates)
df = pd.read_parquet('data/stock_data.parquet')
# 只读部分列(CSV做不到)
df = pd.read_parquet('data/stock_data.parquet', columns=['date', 'symbol', 'close'])
六、踩过的坑
6.1 坑1:前复权的重要性
A股经常有分红、送股操作,除权后价格会出现跳空缺口。比如某股票100元,10送10后价格直接调整到50元——但这不是真的跌了50%,是股本扩大了。
不复权的数据里这个缺口会直接影响收益率计算:
不复权:昨天100元 → 今天50元 = 收益率 -50%(实际是0%)
前复权:历史价格都按比例调整,收益率计算正确
解决方案:始终用前复权数据,adj='qfq'。
6.2 坑2:目标变量构建错误
这个是机器学习的大忌,但很容易忽视。
# 错误做法:target 是今天收盘 vs 昨天收盘,是"过去"的数据
df['target'] = df['close'].pct_change(1)
# 正确做法:target 是明天收盘 vs 今天收盘,才是"未来"的数据
df['target'] = df.groupby('symbol')['close'].shift(-1) / df['close'] - 1
shift(-1) 取的是下一行的值,也就是明天的价格。必须加 groupby('symbol'),否则最后一个交易日的 shift(-1) 会取到下一只股票第一天的价格。
说明:这里说的是训练数据的目标变量构建。和第5篇回测里的"未来函数"不是一回事:
- 目标变量:训练时可以用未来数据(因为是要预测的目标)
- 未来函数:回测时决策不能用未来数据(否则是作弊)
6.3 坑3:GroupBy 的必要性
多只股票合并后,任何涉及时序的计算都必须按股票分组:
# 错误:把茅台和五粮液的数据混在一起算均线
df['ma_20'] = df['close'].rolling(20).mean()
# 正确:每只股票独立计算
df['ma_20'] = df.groupby('symbol')['close'].transform(
lambda x: x.rolling(20).mean()
)
不加 groupby 的后果:茅台的20日均线会用到五粮液前几天的价格,特征完全失真。
七、最终效果
运行 python download_index_data.py,约15分钟完成下载:
获取指数成分股...
沪深300: 300 只
中证500: 500 只
合并去重: 800 只
[ 1/800] 000001.SZ ... 2431 行
[ 2/800] 000002.SZ ... 2296 行
...
[800/800] 689009.SH ... 1015 行
==================================================
✓ 完成!
股票数: 797
总行数: 1,589,404
日期范围: 2015-01-05 ~ 2024-12-31
文件大小: 38.5 MB
保存路径: data/stock_data.parquet
==================================================
797只(3只因数据源缺失被跳过),158万条记录,覆盖10年完整交易数据。
以贵州茅台为例看一下数据质量:
df = pd.read_parquet('data/stock_data.parquet')
maotai = df[df['symbol'] == '600519.SH']
print(f'共 {len(maotai)} 条') # 2431 条,10年无缺失
print(maotai.head(3))
date symbol open high low close volume amount pct_chg change
2015-01-05 600519.SH 142.59 153.58 141.89 152.29 94515.17 1875063.136 6.80 9.70
2015-01-06 600519.SH 150.39 152.32 147.40 148.76 55020.01 1094977.375 -2.32 -3.53
2015-01-07 600519.SH 147.41 150.02 142.86 145.08 54797.84 1063925.641 -2.47 -3.68
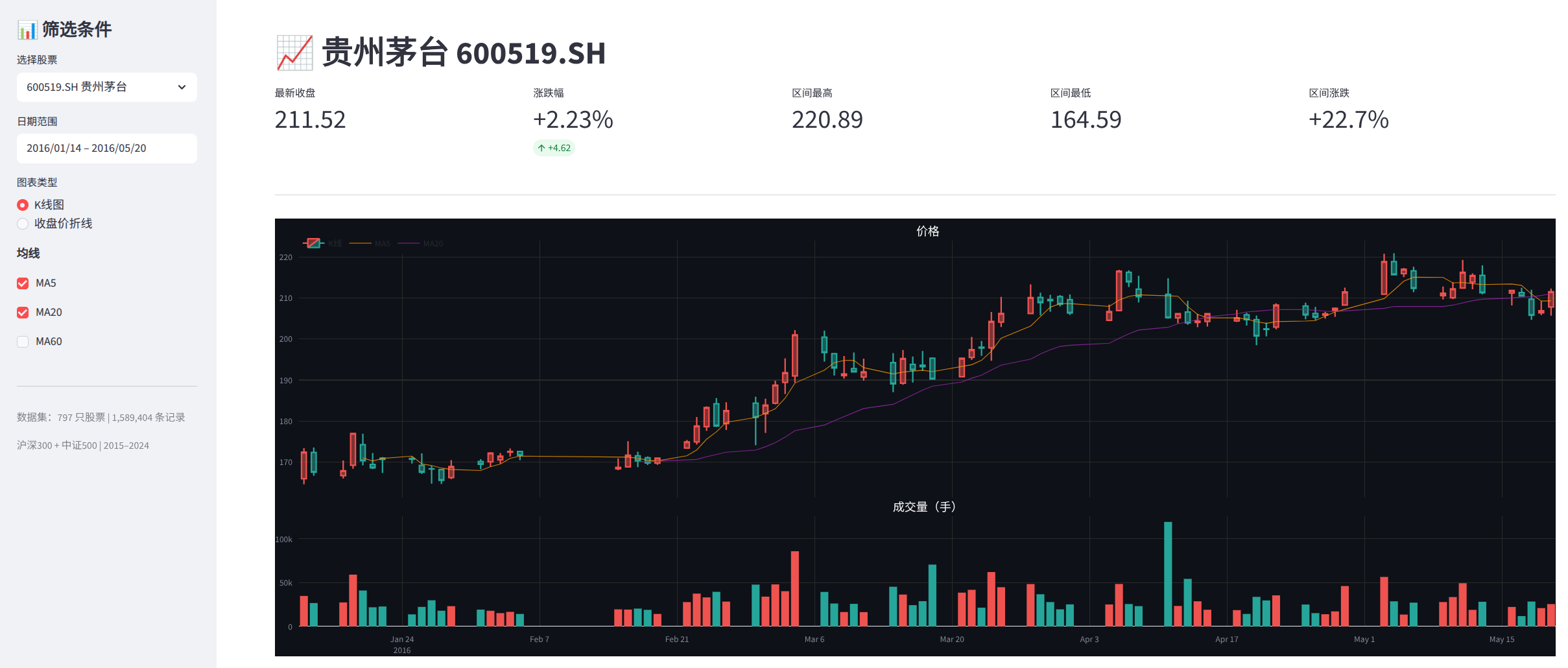
注意2015年茅台显示约142元,是前复权价格(当时实际价格约202元),这是正常的。
八、Web界面
为了方便查看和验证数据,做了一个简单的可视化界面:
streamlit run app.py
功能包括:
- 下拉框选股票(显示代码+中文名,支持搜索)
- 日期范围筛选
- K线图 + 成交量图 + 均线(MA5/MA20/MA60)
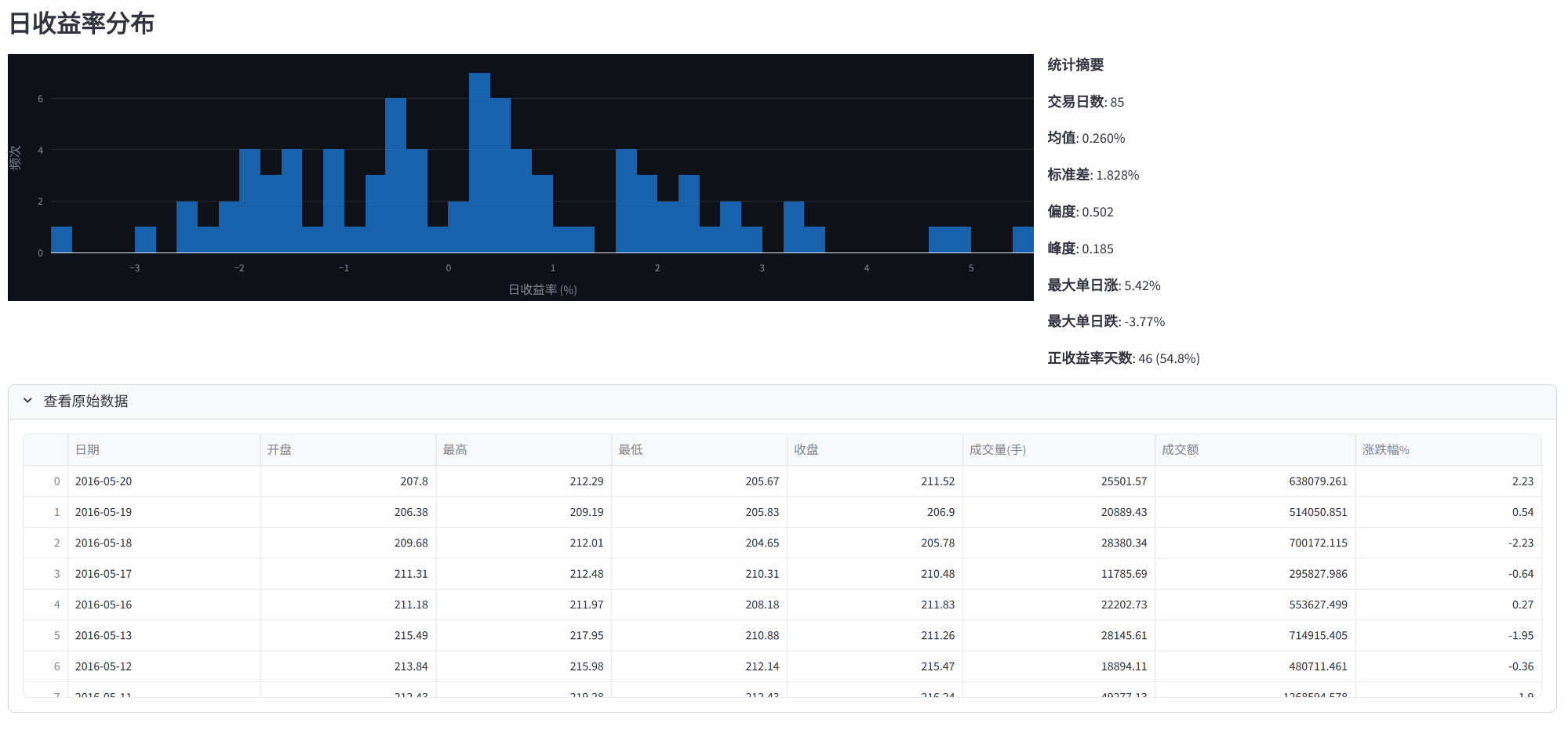
- 日收益率分布直方图
- 基础统计摘要(均值、标准差、偏度、峰度)
- 原始数据表格
九、总结
数据获取看起来简单,细节挺多:
技术选型:
- Tushare Pro 稳定性好,
pro_bar一次调用拿前复权数据 - Parquet 替代 CSV:体积更小,读取更快,类型自动保存
数据规模:
- 沪深300 + 中证500,800只,10年,158万条
- 覆盖牛市(2015/2020)、熊市(2018)、震荡(2022-2023)
数据清洗:
- 三层过滤:缺失值、停牌(成交量=0)、异常涨跌幅(>30%)
- 宁缺毋滥,不造假数据
工程设计:
- 断点续传:单股票缓存,中断可重跑
- 限速:400ms间隔,避免API封禁
- 容错:单只失败不影响整体
下一篇: 第3篇:特征工程